 |
Tansin Jahan, Yanran Guan, Oliver van Kaick, "Semantics-Guided Latent Space Exploration for Shape Generation", Computer Graphics Forum, vol. 40, n. 2, pp. 115-126, 2021. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce an approach to incorporate user guidance into shape generation approaches based on deep networks. Generative networks such as autoencoders and generative adversarial networks are trained to encode shapes into latent vectors, effectively learning a latent shape space that can be sampled for generating new shapes. Our main idea is to enable users to explore the shape space with the use of high-level semantic keywords. Specifically, the user inputs a set of keywords that describe the general attributes of the shape to be generated, e.g., "four legs" for a chair. Then, our method maps the keywords to a subspace of the latent space, where the subspace captures the shapes possessing the specified attributes. The user then explores only this subspace to search for shapes that satisfy the design goal, in a process similar to using a parametric shape model. Our exploratory approach allows users to model shapes at a high level without the need for advanced artistic skills, in contrast to existing methods that allow to guide the generation with sketching or partial modeling of a shape. Our technical contribution to enable this exploration-based approach is the introduction of a label regression neural network coupled with shape encoder/decoder networks. The label regression network takes the user-provided keywords and maps them to distributions in the latent space. We show that our method allows users to explore the shape space and generate a variety of shapes with selected high-level attributes.
@article{jahan2021sgsg,
author = {Tansin Jahan and Yanran Guan and Oliver van Kaick},
title = {Semantics-Guided Latent Space Exploration for Shape Generation},
journal = {Computer Graphics Forum},
volume = {40},
number = {2},
pages = {115--126},
year = 2021,
}
|
 |
Rosa Azami, David Mould, "Image Abstraction through Overlapping Region Growth", Graphics Interface, 2020. [PDF]
[Show Abstract]
[Show Bibtex]
We propose a region-based abstraction of a photograph, where the image plane is covered by overlapping irregularly shaped regions that approximate the image content. We segment regions using a novel region growth algorithm intended to produce highly irregular regions that still respect image edges, different from conventional segmentation methods that encourage compact regions. The final result has reduced detail, befitting abstraction, but still contains some small structures such as highlights; thin features and crooked boundaries are retained, while interior details are softened, yielding a painting-like abstraction effect.
@inproceedings{azami20abstraction,
author = {Rosa Azami and David Mould},
title = {Image Abstraction through Overlapping Region Growth},
booktitle = {Graphics Interface},
year = 2020,
}
|
 |
Yanran Guan, Tansin Jahan, Oliver van Kaick, "Generalized Autoencoder for Volumetric Shape Generation", Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 1082-1088, 2020. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce a 3D generative shape model based on the generalized autoencoder (GAE). GAEs learn a manifold latent space from data relations explicitly provided during training. In our work, we train a GAE for volumetric shape generation from data similarities derived from the Chamfer distance, and with a loss function which is the combination of the traditional autoencoder loss and the GAE loss. We show that this shape model is able to learn more meaningful structures for the latent manifolds of different categories of shapes, and provides better interpolations between shapes when compared to previous approaches such as autoencoders and variational autoencoders.
@inproceedings{guan2020generalized,
author = {Yanran Guan and Tansin Jahan and Oliver van Kaick},
title = {Generalized Autoencoder for Volumetric Shape Generation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
pages = {1082--1088},
year = 2020,
}
|
 |
Azami, Rosa, Lars Doyle, David Mould, "Stipple Removal in Extreme-tone Regions", ACM/EG Expressive Symposium, 2019. [PDF]
[Show Abstract]
[Show Bibtex]
Conventional tone-preserving stippling struggles with extreme-tone regions. Dark regions require immense quantities of stipples, while light regions become littered with stipples that are distracting and, because of their low density, cannot communicate any image features that may be present. We propose a method to address these problems, augmenting existing stippling methods. We will cover dark regions with solid polygons rather than stipples; in light areas, we both preprocess the image to prevent stipple placement in the very lightest areas and postprocess the stipple distribution to remove stipples that contribute little to the image structure. Our modified stipple images have better visual quality than the originals despite using fewer stipples.
@inproceedings{azami19stippling,
author = {Azami, Rosa and Doyle, Lars and Mould, David},
title = {Stipple Removal in Extreme-tone Regions},
booktitle = {ACM/EG Expressive Symposium},
year = 2019,
}
|
 |
Doyle, Lars, Forest Anderson, Ehren Choy, David Mould, "Automated pebble mosaic stylization of images", Computational Visual Media, vol. 5, n. 1, pp. 33-44, 2019. [PDF]
[Show Abstract]
[Show Bibtex]
Digital mosaics have usually used regular tiles, simulating the historical "tessellated" mosaics. In this paper, we present a method for synthesizing pebble mosaics, a historical mosaic style in which the tiles are rounded pebbles. We address both the tiling problem, where pebbles are distributed over the image plane so as to approximate the input image content, and the problem of geometry, creating a smooth rounded shape for each pebble. We adapt SLIC, simple linear iterative clustering, to obtain elongated tiles conforming to image content, and smooth the resulting irregular shapes into shapes resembling pebble cross-sections. Then, we create an interior and exterior contour for each pebble and solve a Laplace equation over the region between them to obtain heightfield geometry. The resulting pebble set approximates the input image while presenting full geometry that can be rendered and textured for a highly detailed representation of a pebble mosaic.
@article{doyle2019,
author = {Doyle, Lars and Anderson, Forest and Choy, Ehren and Mould, David},
title = {Automated pebble mosaic stylization of images},
journal = {Computational Visual Media},
volume = {5},
number = {1},
pages = {33--44},
year = 2019,
}
|
 |
Javid, Ali Sattari, Lars Doyle, David Mould, "Irregular pebble mosaics with sub-pebble detail", ACM/EG Expressive Symposium, 2019. [DOI]
[Show Abstract]
[Show Bibtex]
Pebble mosaics convey images through an irregular tiling of rounded pebbles. Past work used relatively uniform tile sizes. We show how to create detailed representations of input photographs in a pebble mosaic style; we first create pebble shapes through a variant of k-means, then compute sub-pebble detail with textured, two-tone pebbles. We use a custom distance function to ensure that pebble sizes adapt to local detail and orient to local feature directions, for an overall effect of high fidelity to the input photograph despite the constraints of the pebble style.
@inproceedings{javid19pebbles,
author = {Javid, Ali Sattari and Doyle, Lars and Mould, David},
title = {Irregular pebble mosaics with sub-pebble detail},
booktitle = {ACM/EG Expressive Symposium},
year = 2019,
}
|
 |
Lars Doyle, David Mould, "Augmenting Photographs with Textures Using the Laplacian Pyramid", The Visual Computer, to appear, 2018. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce a method to stylize photographs with auxiliary textures, by means of the Laplacian pyramid. Laplacian pyramid coefficients from a synthetic texture are combined with the coefficients from the original image by means of a smooth maximum function. The final result is a stylized image which maintains the structural characteristics from the input, including edges, color, and existing texture, while enhancing the image with additional fine-scale details. Further, we extend patch-based texture synthesis to include a guidance channel so that texture structures are aligned with an orientation field, obtained through the image structure tensor.
@article{doyle18pyramid,
author = {Lars Doyle and David Mould},
title = {Augmenting Photographs with Textures Using the Laplacian Pyramid},
journal = {The Visual Computer},
pages = {to appear},
year = 2018,
}
|
 |
Diego Gonzalez, Oliver van Kaick, "3D Synthesis of Man-made Objects based on Fine-grained Parts.", Computers & Graphics (Proc. SMI), vol. 74, pp. 150-160, 2018. [PDF]
[Show Abstract]
[Show Bibtex]
We present a novel approach for 3D shape synthesis from a collection of existing models. The main idea of our approach is to synthesize shapes by recombining fine-grained parts extracted from the existing models based purely on the objects' geometry. Thus, unlike most previous works, a key advantage of our method is that it does not require a semantic segmentation, nor part correspondences between the shapes of the input set. Our method uses a template shape to guide the synthesis. After extracting a set of fine-grained segments from the input dataset, we compute the similarity among the segments in the collection and segments of the template using shape descriptors. Next, we use the similarity estimates to select, from the set of fine-grained segments, compatible replacements for each part of the template. By sampling different segments for each part of the template, and by using different templates, our method can synthesize many distinct shapes that have a variety of local fine details. Additionally, we maintain the plausibility of the objects by preserving the general structure of the template. We show with several experiments performed on different datasets that our algorithm can be used for synthesizing a wide variety of man-made objects.
@article{gonzalez18finegrained,
author = {Diego Gonzalez and Oliver van Kaick},
title = {3D Synthesis of Man-made Objects based on Fine-grained Parts.},
journal = {Computers & Graphics (Proc. SMI)},
volume = {74},
pages = {150--160},
year = 2018,
}
|
 |
Ruizhen Hu, Manolis Savva, Oliver van Kaick, "Functionality Representations and Applications for Shape Analysis", Computer Graphcis Forum (Eurographics State-of-the-art Reports), vol. 37, n. 2, pp. 603-624, 2018. [PDF]
[Show Abstract]
[Show Bibtex]
A central goal of computer graphics is to provide tools for designing and simulating real or imagined artifacts. An understanding of functionality is important in enabling such modeling tools. Given that the majority of man-made artifacts are designed to serve a certain function, the functionality of objects is often reflected by their geometry, the way that they are organized in an environment, and their interaction with other objects or agents. Thus, in recent years, a variety of methods in shape analysis have been developed to extract functional information about objects and scenes from these different types of cues. In this report, we discuss recent developments that incorporate functionality aspects into the analysis of 3D shapes and scenes. We provide a summary of the state-of-the-art in this area, including a discussion of key ideas and an organized review of the relevant literature. More specifically, the report is structured around a general definition of functionality from which we derive criteria for classifying the body of prior work. This definition also facilitates a comparative view of methods for functionality analysis. We focus on studying the inference of functionality from a geometric perspective, and pose functionality analysis as a process involving both the geometry and interactions of a functional entity. In addition, we discuss a variety of applications that benefit from an analysis of functionality, and conclude the report with a discussion of current challenges and potential future works.
@article{hu18func-star,
author = {Ruizhen Hu and Manolis Savva and Oliver van Kaick},
title = {Functionality Representations and Applications for Shape Analysis},
journal = {Computer Graphcis Forum (Eurographics State-of-the-art Reports)},
volume = {37},
number = {2},
pages = {603--624},
year = 2018,
}
|
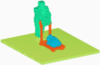 |
Ruizhen Hu, Zihao Yan, Jingwen Zhang, Oliver van Kaick, Ariel Shamir, Hao Zhang, Hui Huang, "Predictive and Generative Neural Networks for Object Functionality", ACM Trans. on Graphics (Proc. SIGGRAPH), vol. to appear, 2018. [PDF]
[Show Abstract]
[Show Bibtex]
Humans can predict the functionality of an object even without any surroundings, since their knowledge and experience would allow them to "hallucinate" the interaction or usage scenarios involving the object. We develop predictive and generative deep convolutional neural networks to replicate this feat. Specifically, our work focuses on functionalities of man-made 3D objects characterized by human-object or object-object interactions. Our networks are trained on a database of scene contexts, called interaction contexts, each consisting of a central object and one or more surrounding objects, that represent object functionalities. Given a 3D object in isolation, our functional similarity network (fSIM-NET), a variation of the triplet network, is trained to predict the functionality of the object by inferring functionality-revealing interaction contexts involving the object. fSIM-NET is complemented by a generative network (iGEN-NET) and a segmentation network (iSEG-NET). iGEN-NET takes a single voxelized 3D object and synthesizes a voxelized surround, i.e., the interaction context which visually demonstrates the object's functionalities. iSEG-NET separates the interacting objects into different groups according to their interaction types.
@article{hu18iconnet,
author = {Ruizhen Hu and Zihao Yan and Jingwen Zhang and Oliver van Kaick and Ariel Shamir and Hao Zhang and Hui Huang},
title = {Predictive and Generative Neural Networks for Object Functionality},
journal = {ACM Trans. on Graphics (Proc. SIGGRAPH)},
volume = {to appear},
year = 2018,
}
|
|
Carlos Aviles, "Image Stylization using Depth Information for Hatching and Engraving effects", Carleton University, 2017. [PDF]
[Show Abstract]
[Show Bibtex]
In this thesis inspired by artists such as Gustave Doré and copperplate engravers, we present a new approach for producing a sketch-type hatching effect as well as engraving art seen in the US dollar bills using depth maps as input. The approach uses the acquired depth to generate pen-and-ink type of strokes that exaggerate surface characteristics of faces and objects. The background on this area is presented with an emphasis on line drawing, pen-and-ink illustrations, engraving art and other artistic styles. The patterns generated are composed of parallel lines that change their directionality smoothly while avoiding intersections between them. The style communicates tone and surface characteristics using curve deformation, thickness, density, and spacing while at the same time adding crosshatching effects. This is achieved with our algorithmic approach which uses the data to perform operations that deforms patterns. The components of our methodology and algorithms are detailed, as well as the equations that govern these effects. This work also presents an array of different results by varying parameters or by rendering variations.
@thesis{aviles17engraving,
author = {Carlos Aviles},
title = {Image Stylization using Depth Information for Hatching and Engraving effects},
booktitle = {Carleton University},
year = 2017,
}
|
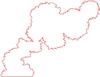 |
Ramin Modarresiyazdi, "Procedural 2D Cumulus Clouds Using Snaxels", Carleton University, 2017. [PDF]
[Show Abstract]
[Show Bibtex]
This thesis develops a procedural modeling algorithm to model cumulus clouds or objects with similar shapes and surfaces in 2 dimensions. Procedural modeling of clouds has been extensively studied and researched in computer graphics. Most of the literature follows physical characteristics of clouds and tries to model them using physically-inspired simulations. Cumulus clouds, volcanic ash clouds and similar naturally shaped bodies come in many different shapes and sizes, yet the surfaces share similarities and possess high irregularities in details which makes them difficult to model using conventional modeling techniques. We propose a framework for modeling such surfaces and shapes with minimal user intervention. Our approach uses an active contour model which propagates through a tessellation. In this thesis, we will describe our technique for modeling cloud looking structures and we will present our results of our algorithm and show case a simple user interactive framework as well.
@thesis{ramin17clouds,
author = {Ramin Modarresiyazdi},
title = {Procedural 2D Cumulus Clouds Using Snaxels},
booktitle = {Carleton University},
year = 2017,
}
|
 |
Rosa Azami, David Mould, "Detail and Color Enhancement in Photo Stylization", Expressive, 2017. [PDF]
[Show Abstract]
[Show Bibtex]
Abstraction in non-photorealistic rendering reduces the amount of detail, yet non-essential details can improve visual interest and thus make an image more appealing. In this paper, we propose an automatic system for photo manipulation that brightens an image and alters the detail levels. The process first applies an edge-preserving abstraction process to an input image, then uses the residual to reintroduce and exaggerate details in areas near strong edges. At the same time, image regions further from strong edges are brightened. The final result is a lively mixture of abstraction and enhanced detail.
@inproceedings{azami17,
author = {Rosa Azami and David Mould},
title = {Detail and Color Enhancement in Photo Stylization},
booktitle = {Expressive},
year = 2017,
}
|
 |
David Mould, Paul Rosin, "Developing and Applying A Benchmark for Evaluating Image Stylization", Computers & Graphics, 2017. [PDF]
[Show Abstract]
[Show Bibtex]
The non-photorealistic rendering community has had difficulty evaluating its research results. Other areas of computer graphics, and related disciplines such as computer vision, have made progress by comparing algorithms' performance on common datasets, or benchmarks. We argue for the benefits of establishing a benchmark image set to which image stylization methods can be applied, simplifying the comparison of methods, and broadening the testing to which a given method is subjected. We propose a set of benchmark images, representing a range of possible subject matter and image features of interest to researchers, and we describe the policies, tradeoffs, and reasoning that led us to the particular images in the set. Then, we apply six previously existing stylization algorithms to the benchmark images; we discuss observations arising from the interactions between the algorithms and the benchmark images. Inasmuch as the benchmark images were able to thoroughly exercise the algorithms and produce new material for discussion, we can conclude that the benchmark will be effective for its stated aim.
@article{mould17benchmark,
author = {David Mould and Paul Rosin},
title = {Developing and Applying A Benchmark for Evaluating Image Stylization},
journal = {Computers & Graphics},
year = 2017,
}
|
 |
Ruizhen Hu, Wenchao Li, Oliver van Kaick, Hui Huang, Melinos Averkiou, Daniel Cohen-Or, Hao Zhang, "Co-Locating Style-Defining Elements on 3D Shapes", ACM Trans. Graph., vol. 36, n. 3, pp. 33:1-33:15, 2017. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce a method for co-locating style-defining elements over a set of 3D shapes. Our goal is to translate high-level style descriptions, such as "Ming" or "European" for furniture models, into explicit and localized regions over the geometric models that characterize each style. For each style, the set of style-defining elements is defined as the union of all the elements that are able to discriminate the style. Another property of the style-defining elements is that they are frequently-occurring, reflecting shape characteristics that appear across multiple shapes of the same style. Given an input set of 3D shapes spanning multiple categories and styles, where the shapes are grouped according to their style labels, we perform a cross-category co-analysis of the shape set to learn and spatially locate a set of defining elements for each style. This is accomplished by first sampling a large number of candidate geometric elements, and then iteratively applying feature selection to the candidates, to extract style-discriminating elements until no additional elements can be found. Thus, for each style label, we obtain sets of discriminative elements that together form the superset of defining elements for the style. We demonstrate that the co-location of style-defining elements allows us to solve problems such as style classification, and enables a variety of applications such as style-revealing view selection, style-aware sampling, and style-driven modeling for 3D shapes.
@article{hu2017style,
author = {Ruizhen Hu and Wenchao Li and Oliver van Kaick and Hui Huang and Melinos Averkiou and Daniel Cohen-Or and Hao Zhang},
title = {Co-Locating Style-Defining Elements on 3D Shapes},
journal = {ACM Trans. Graph.},
volume = {36},
number = {3},
pages = {33:1--33:15},
year = 2017,
}
|
 |
Ruizhen Hu, Wenchao Li, Oliver van Kaick, Ariel Shamir, Hao Zhang, Hui Huang, "Learning to Predict Part Mobility from a Single Static Snapshot", ACM Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 36, n. 6, pp. 227:1-227:13, 2017. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce a method for learning a model for the mobility of parts in 3D objects. Our method allows not only to understand the dynamic functionalities of one or more parts in a 3D object, but also to apply the mobility functions to static 3D models. Specifically, the learned part mobility model can predict mobilities for parts of a 3D object given in the form of a single static snapshot reflecting the spatial configuration of the object parts in 3D space, and transfer the mobility from relevant units in the training data. The training data consists of a set of mobility units of different motion types. Each unit is composed of a pair of 3D object parts (one moving and one reference part), along with usage examples consisting of a few snapshots capturing different motion states of the unit. Taking advantage of a linearity characteristic exhibited by most part motions in everyday objects, and utilizing a set of part-relation descriptors, we define a mapping from static snapshots to dynamic units. This mapping employs a motion-dependent snapshot-to-unit distance obtained via metric learning. We show that our learning scheme leads to accurate motion prediction from single static snapshots and allows proper motion transfer. We also demonstrate other applications such as motion-driven object detection and motion hierarchy construction.
@article{hu17icon3,
author = {Ruizhen Hu and Wenchao Li and Oliver van Kaick and Ariel Shamir and Hao Zhang and Hui Huang},
title = {Learning to Predict Part Mobility from a Single Static Snapshot},
journal = {ACM Trans. on Graphics (Proc. SIGGRAPH Asia)},
volume = {36},
number = {6},
pages = {227:1--227:13},
year = 2017,
}
|
 |
Ruizhen Hu, Oliver van Kaick, Bojian Wu, Hui Huang, Ariel Shamir, Hao Zhang, "Learning How Objects Function via Co-Analysis of Interactions", ACM Trans. on Graphics (Proc. SIGGRAPH), vol. 35, n. 4, pp. 47:1-47:13, 2016. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce a co-analysis method which learns a functionality model for an object category, e.g., strollers or backpacks. Like previous works on functionality, we analyze object-to-object interactions and intra-object properties and relations. Differently from previous works, our model goes beyond providing a functionality-oriented descriptor for a single object; it prototypes the functionality of a category of 3D objects by co-analyzing typical interactions involving objects from the category. Furthermore, our co-analysis localizes the studied properties to the specific locations, or surface patches, that support specific functionalities, and then integrates the patch-level properties into a category functionality model. Thus our model focuses on the how, via common interactions, and where, via patch localization, of functionality analysis. Given a collection of 3D objects belonging to the same category, with each object provided within a scene context, our co-analysis yields a set of proto-patches, each of which is a patch prototype supporting a specific type of interaction, e.g., stroller handle held by hand. The learned category functionality model is composed of proto-patches, along with their pairwise relations, which together summarize the functional properties of all the patches that appear in the input object category. With the learned functionality models for various object categories serving as a knowledge base, we are able to form a functional understanding of an individual 3D object, without a scene context. With patch localization in the model, functionality-aware modeling, e.g, functional object enhancement and the creation of functional object hybrids, is made possible.
@article{hu16icon2,
author = {Ruizhen Hu and Oliver van Kaick and Bojian Wu and Hui Huang and Ariel Shamir and Hao Zhang},
title = {Learning How Objects Function via Co-Analysis of Interactions},
journal = {ACM Trans. on Graphics (Proc. SIGGRAPH)},
volume = {35},
number = {4},
pages = {47:1--47:13},
year = 2016,
}
|
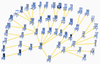 |
Noa Fish, Oliver van Kaick, Amit Bermano, Daniel Cohen-Or, "Structure-oriented Networks of Shape Collections", ACM Trans. on Graphics (Proc. SIGGRAPH Asia), vol. 35, n. 6, to appear, 2016. [PDF]
[Show Abstract]
[Show Bibtex]
We introduce a co-analysis technique designed for correspondence inference within large shape collections. Such collections are naturally rich in variation, adding ambiguity to the notoriously difficult problem of correspondence computation. We leverage the robustness of correspondences between similar shapes to address the difficulties associated with this problem. In our approach, pairs of similar shapes are extracted from the collection, analyzed and matched in an efficient and reliable manner, culminating in the construction of a network of correspondences that connects the entire collection. The correspondence between any pair of shapes then amounts to a simple propagation along the minimax path between the two shapes in the network. At the heart of our approach is the introduction of a robust, structure-oriented shape matching method. Leveraging the idea of projective analysis, we partition 2D projections of a shape to obtain a set of 1D ordered regions, which are both simple and efficient to match. We lift the matched projections back to the 3D domain to obtain a pairwise shape correspondence. The emphasis given to structural compatibility is a central tool in estimating the reliability and completeness of a computed correspondence, uncovering any non-negligible semantic discrepancies that may exist between shapes. These detected differences are a deciding factor in the establishment of a network aiming to capture local similarities. We demonstrate that the combination of the presented observations into a co-analysis method allows us to establish reliable correspondences among shapes within large collections.
@article{fish16corrnet,
author = {Noa Fish and Oliver van Kaick and Amit Bermano and Daniel Cohen-Or},
title = {Structure-oriented Networks of Shape Collections},
journal = {ACM Trans. on Graphics (Proc. SIGGRAPH Asia)},
volume = {35},
number = {6},
pages = {to appear},
year = 2016,
}
|
 |
David Mould, Paul Rosin, "A Benchmark Image Set for Evaluating Stylization", Expressive, 2016. [PDF]
[Show Abstract]
[Show Bibtex]
The non-photorealistic rendering community has had difficulty evaluating its research results. Other areas of computer graphics, and related disciplines such as computer vision, have made progress by comparing algorithms' performance on common datasets, or benchmarks. We argue for the benefits of establishing a benchmark image set to which image stylization methods can be applied, making comparisons between methods simpler, and encouraging more thorough testing of individual methods. We propose a preliminary set of benchmark images, chosen to represent a range of possible subject matter and image features of interest to researchers, and we describe the policies, tradeoffs, and reasoning that led us to the particular images in the set.
@inproceedings{mould16benchmark,
author = {David Mould and Paul Rosin},
title = {A Benchmark Image Set for Evaluating Stylization},
booktitle = {Expressive},
year = 2016,
}
|
 |
Lars Doyle, David Mould, "Painted Stained Glass", Expressive, 2016. [PDF]
[Show Abstract]
[Show Bibtex]
We propose a new region-based method for stained glass rendering of an input photograph. We achieve more regular region sizes than previous methods by using simple linear iterative clustering, or SLIC, to obtain tile boundaries. The SLIC regions respect image edges but provide an oversegmentation suitable for stained glass. We distinguish between important boundaries that match image edges, and unimportant boundaries that do not; we then resegment regions with unimportant boundaries to create more regular regions. We assign colors to stained glass tiles; lastly, we apply a painting layer to the simplified image, restoring fine details that cannot be conveyed by the tile shapes alone. This last step is analogous to the overpainting done in real-world stained glass. The outcome is a stylized image that offers a better representation of the original image content than has been available from earlier stained glass filters, while still conveying the sense of a stained glass image.
@inproceedings{doyle16glass,
author = {Lars Doyle and David Mould},
title = {Painted Stained Glass},
booktitle = {Expressive},
year = 2016,
}
|